Unraveling Cause-and-Effect With AI: A Step Towards Automated Intelligent Causal Discovery
Unraveling Cause-and-Effect With AI: A Step Towards Automated Intelligent Causal Discovery
November 27, 2025
By Maxim Laletin
What is Causal Discovery?
In the world of data-driven decision-making, understanding why things happen is often more valuable than knowing what actually happens. This is the essence of causal discovery — the process of uncovering cause-and-effect relationships hidden within data. Unlike traditional correlation-based analytics, causal discovery aims to answer questions like “What drives customer churn?” or “Which operational change will actually improve sales?”.
Historically, researchers have pursued causal discovery in two complementary ways — through human-driven reasoning and algorithmic automation. In its most traditional form, experts explore potential cause-and-effect relationships by combining data analysis with insight, intuition, and deep domain knowledge. Over time, this manual process has been augmented by statistical and computational methods designed to automate parts of the search for causal structures. Techniques such as constraint-based algorithms (like the PC algorithm), and score-based approaches (such as GES) aim to infer causal relationships directly from numerical data. Yet, even these sophisticated tools rely on strong assumptions — for example, that the data is complete, clean, and generated under stable conditions — and ultimately still depend on domain expertise to guide, interpret, and validate their findings. Whether causal discovery is performed by people or machines, contextual knowledge remains indispensable.
For businesses, causal discovery has powerful implications. From optimizing marketing strategies to managing supply chains or predicting policy impacts, understanding the drivers behind observed outcomes can lead to more confident, evidence-based decisions. Yet, because traditional causal inference methods require deep expertise and high-quality data, their adoption outside research settings has been limited.
This is where Large Language Models (LLMs) may offer a new path forward. Trained on vast corpora of human knowledge, LLMs implicitly encode rich domain context across industries, sciences, and everyday reasoning. This makes them promising partners in causal discovery — not by replacing numerical rigor, but by infusing causal analysis with contextual understanding. In this post we’ll explore how LLMs can help surface, interpret, and even hypothesize causal relationships in ways that blend data-driven insight with real-world knowledge.
Representing Causality with Graphs
At the heart of most causal discovery methods lies a simple but powerful idea: representing cause-and-effect relationships as a graph. In such a graph — known as a Directed Acyclic Graph (DAG) — each node corresponds to a variable (for instance, “Marketing Spend,” “Customer Engagement,” or “Revenue”), and each arrow represents a causal influence from one variable to another. The “acyclic” part means that these arrows never loop back on themselves — in other words, causes lead to effects, not the other way around.
To make this idea more tangible, imagine a simple system describing how plants grow and produce oxygen. Factors such as the amount of light, water, and nutrients all contribute to a plant’s overall growth factor. In turn, this growth determines both the amount of oxygen produced and, in the case of fruit-bearing plants, the number of fruits each plant yields.
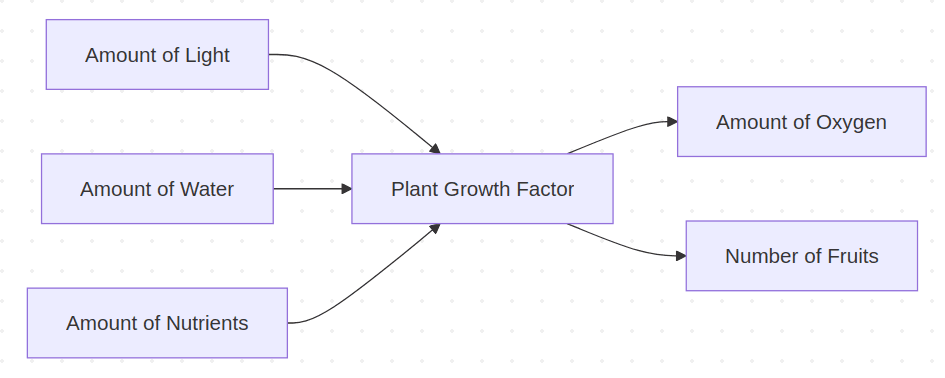
This example illustrates how causal graphs help disentangle direct and indirect effects — showing not only that one variable influences another, but also how that influence is transmitted through intermediate factors. This structure allows researchers and decision-makers to visualize how different factors interact and where interventions might have the greatest impact. Traditionally, constructing such graphs has required either complex statistical algorithms or expert judgment — and ideally, both.
LLMs introduce yet another way to approach this process. When provided with metadata about a dataset — such as variable names, descriptions, and the surrounding context — an LLM can draw on its vast embedded knowledge to hypothesize plausible causal links between variables. Instead of treating data as an isolated set of numbers, the model interprets it in light of broader real-world relationships it has “learned” from text, research papers, and domain knowledge across industries.
Let's consider a quite simple, but realistic and practical example of how LLMs can be implemented to infer the underlying causal graph.
A Practical Example: Using LLMs to Generate a Causal Graph
For this demonstration we use the OpenAI API to prompt the model for a structured causal analysis.
client = OpenAI( api_key= ... )
response = client.responses.parse(
model=gpt-5-mini,
input=[
{"role": "system", "content": prompt},
{"role": "user", "content": dataset_info},
],
text_format = CausalGraph
)
The model (gpt-5-mini) is instructed through a carefully designed system–user input pair: the system message defines the overall task and constraints:
# Role and Objective
You are a specialist on causality, you receive the names of the statistic variables in the text format
and the context in which these variables appear and your task is to construct a causal graph
according to the structured output format which will reflect the causal connections between these variables...
while the user message provides the list of variables along with a short context describing how these variables interact in the real world. Let's consider the following variables that appear in media mix modelling -- Website Visits, Social Media Spend, Brand Awareness, Sales Volume and TV Advertising Spend:
dataset_info = "List of variables: Website Visits, Social Media Spend, Brand Awareness, Sales Volume, TV Advertising Spend;
Context: In media mix modeling, marketers analyze how different advertising channels interact to drive customer engagement and sales."
The key to guiding the model effectively lies in the prompt design. In particular, we include a clear definition of causality, which ensures the model interprets relationships as genuine cause-and-effect links rather than mere correlations:
If A and B represent variables, we say that A causes B in the given context if, and only if, the following conditions are satisfied:
(i) Manipulating A can in principle lead to a change in B;
(ii) Manipulating B can never lead to a change in A.
We also leverage the model’s structured output capabilities. Instead of returning free-form text, the response is parsed into a predefined Pydantic object (CausalGraph) that mirrors the structure of a causal graph. This object contains lists of nodes and edges, as well as an explanation field that captures the model’s reasoning behind the proposed relationships.
ID_PATTERN = r"^[A-Za-z0-9_]+$"
class CausalNode(BaseModel):
id: str = Field(pattern=ID_PATTERN)
name: str
class CausalEdge(BaseModel):
source: str = Field(pattern=ID_PATTERN)
target: str = Field(pattern=ID_PATTERN)
class CausalGraph(BaseModel):
nodes: List[CausalNode]
edges: List[CausalEdge]
explanation: Optional[str] = None
By using this structured format, we can both validate the internal consistency of the model’s output and inspect its reasoning in a transparent, machine-readable way.
Finally, we get the following output of our query that can be represented in the form of a mermaid chart:
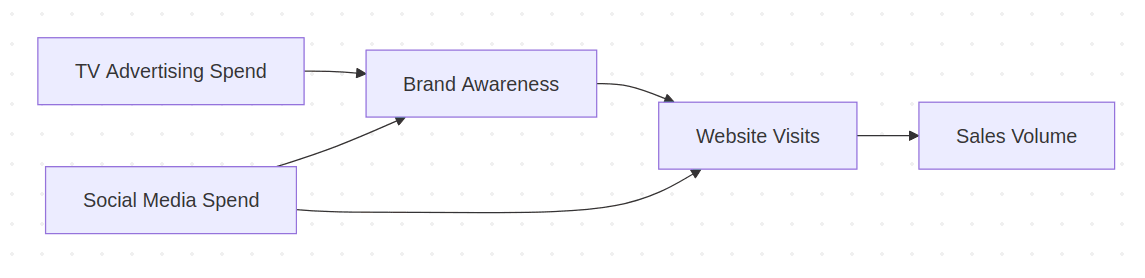
The explanation that the LLM provides together with the causal graph demonstrates that the reasoning behind arranging these variables into a causal structure is well-motivated and combines specific domain understanding with the ability to follow the proposed definition of causality.
Reasoning and assumptions based on media-mix modeling:
- TV Advertising Spend -> Brand Awareness: TV is a broad-reach channel whose primary causal effect is to increase customers' awareness of the brand. Manipulating TV spend can change brand awareness; awareness does not cause TV spend.
- Social Media Spend -> Brand Awareness: Social media advertising similarly raises brand awareness (and again awareness does not cause ad spend).
- Social Media Spend -> Website Visits: Social media often drives direct site traffic (clicks, direct-response ads). Manipulating social spend can change visits. This is modeled as a direct effect rather than routed only through brand awareness.
- Brand Awareness -> Website Visits: Higher awareness increases the propensity of consumers to visit the website (e.g., search or navigate to the site). Manipulating awareness can change visits; visits do not cause prior awareness.
- Website Visits -> Sales Volume: Visits are the proximate conversion funnel step that causally lead to online sales volume (higher visits can increase sales). Sales do not cause earlier visits.
Edges omitted and why (to avoid transitive edges and reflect primary causal pathways):
- No edges between the two ad spends: spending on one channel is not modeled as causing spending on the other (they are treated as exogenous marketing inputs).
- No direct TV Advertising Spend -> Website Visits edge: TV effects on visits are modeled as operating primarily via increased brand awareness (TV -> Brand Awareness -> Website Visits). Adding TV -> Website Visits would create a transitive edge given the chosen structure.
- No direct edges from either ad spend straight to Sales Volume: in this graph we represent ad effects on sales as mediated through Brand Awareness and Website Visits (ad spend -> awareness/visits -> sales). A direct spend -> sales edge would duplicate those mediated paths and create transitive/redundant connections.
Although the example is minimal by design, it clearly demonstrates the significant capabilities of LLMs in causal reasoning and discovery — achieved entirely without access to underlying data.
Enhancing LLM-Based Causal Discovery
While our simple example shows that LLMs can reason about causal structures even without direct access to data, this approach can be developed much further. Several promising research directions are emerging that blend language models, classical algorithms, and statistical inference into more robust causal discovery frameworks.
1. Scaling to larger datasets with efficient algorithms
One natural extension is to combine LLM reasoning with scalable algorithmic realizations such as breadth-first search (BFS)-based approaches for causal discovery. These methods are capable of handling large, complex datasets by exploring possible causal links in a structured, layer-by-layer fashion. Recent research demonstrates how BFS-inspired strategies can significantly improve computational efficiency and scalability in causal graph construction.
2. Agentic collaboration for causal reasoning
Another emerging direction involves agentic approaches, where multiple specialized LLM agents collaborate—some proposing causal hypotheses, others validating or refining them. Through dialogue and reasoning, these agents can work toward generating the most plausible causal graph or selecting the most appropriate numerical algorithm for a given dataset. This kind of multi-agent system, exemplified in studies like this one, represents a step toward autonomous, self-improving causal discovery pipelines.
3. Combining metadata with statistical information
LLMs can also be paired with traditional data-analysis techniques. By enriching the model’s contextual understanding (drawn from dataset metadata) with empirical statistical signals—such as correlations, conditional independencies, or regression-based effects—we can create hybrid systems that integrate human-like reasoning with numerical rigor. This dual perspective enables the model not only to hypothesize causal relationships but also to test and refine them based on real data.
4. From LLM insights to probabilistic modeling
Finally, insights generated by LLMs about a dataset’s causal structure can be used to construct probabilistic models in frameworks such as PyMC. These models enable counterfactual analysis—testing “what if” scenarios to verify whether the inferred causal relationships hold true under different interventions. Following the methodology illustrated in this example, such integration allows practitioners to rigorously evaluate and validate the causal graphs proposed by LLMs using real-world data.
Together, these avenues point toward a future where causal discovery is not only automated but adaptive—combining reasoning, collaboration, and computation to produce deeper, more reliable insights from data.
Why Causal Discovery Matters for Business
Causal discovery isn’t just an academic exercise—it’s a practical capability with direct implications for how businesses understand, plan, and grow. In a world driven by data, companies often rely on predictive analytics and correlations to guide decisions. However, knowing that two factors are correlated is not the same as understanding which one drives the other. Causal discovery bridges that gap, revealing the underlying mechanisms behind business outcomes.
There are several reasons why this matters:
- Better decision-making: By identifying true cause-and-effect relationships, organizations can make strategic choices that actually move the needle—whether in marketing, operations, or product strategy.
- Optimized resource allocation: Understanding which actions lead to desired outcomes helps allocate budgets more effectively, reducing waste and maximizing ROI.
- Scenario planning and risk reduction: Causal models enable “what-if” analyses, allowing teams to simulate the effects of interventions before implementing them in the real world.
- Explainability and trust: In regulated or high-stakes industries, causal reasoning offers transparency and justification for data-driven decisions, which is often a requirement for compliance or stakeholder confidence.
Recent developments show that automated, agentic systems are already being applied to practical business problems. For instance, PyMC Labs has introduced an AI Marketing Mix Modeling Agent that combines LLMs and Bayesian inference to autonomously perform media mix modeling—an essential tool for understanding how different marketing channels contribute to sales.
The approaches discussed here—using LLMs for causal graph generation, multi-agent reasoning, and probabilistic validation—represent a natural generalization of this idea. They could extend beyond marketing to domains such as finance, logistics, operations, and human resources. By automating the discovery and validation of causal relationships across diverse datasets, businesses can move toward a new generation of AI-driven decision intelligence, where insights are not only predictive but truly explanatory.
Want to learn more about AI solutions for business?
As part of our ongoing R&D efforts, PyMC Labs is exploring new applications of AI to help organizations work smarter, faster, and more creatively.
- AI-based Customer Research: Faster & Cheaper Surveys with Synthetic Consumers
- LLMs and Price Reasoning: Toward an Industry Benchmark
- AI modelling agent that generates hallucination-free Bayesian models
Stay tuned for exciting updates from out AI Innovation Lab and contact us to discuss what we can do for your enterprise.