AI-based Customer Research: Faster & Cheaper Surveys with Synthetic Consumers
AI-based Customer Research: Faster & Cheaper Surveys with Synthetic Consumers
November 21, 2025
By Benjamin F. Maier
Consumer research costs corporations billions annually, yet it still struggles with panel bias, limited scale, and noisy results. What if synthetic consumers powered by large language models (LLMs) could replicate human survey responses with high accuracy while providing richer qualitative feedback?
That's exactly what PyMC Labs researchers just proved in a new preprint that's changing how we think about AI-powered market research.
The Problem with Asking AI for Numbers
When companies first tried using LLMs as synthetic consumers, they hit a wall. Ask LLMs directly for a 1-5 rating about purchase intent given a product concept, and you get unrealistic distributions — too many "3s," hardly any extreme responses, and patterns that don't match real human behavior. The conventional wisdom? LLMs just aren't reliable survey takers.
Our PyMC Labs team showed that's wrong. The problem wasn't the models, it was how we were asking them questions.
The Breakthrough: Semantic Similarity Rating (SSR)
Instead of forcing LLMs to pick a number, the research team developed a two-step approach:
- Step One: Let AI respond naturally in text (like humans actually think about purchase intent)
- Step Two: Map that response to a rating distribution on the 1-5 scale using semantic similarity, comparing the AI's statement to reference anchors for each point
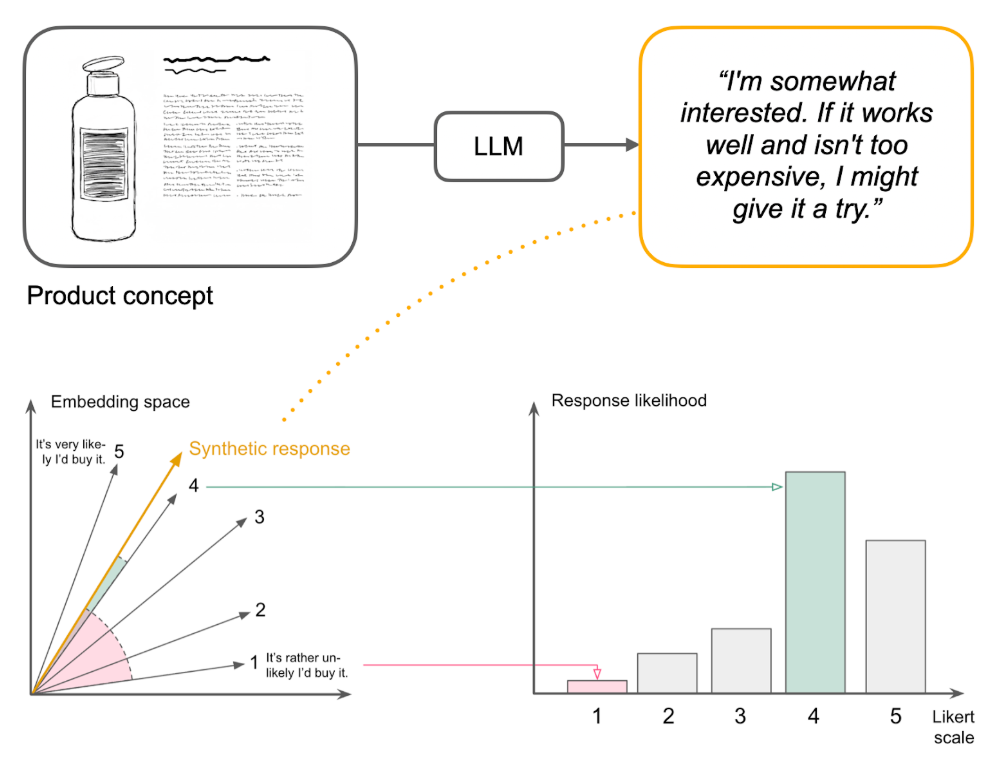
The results? Using 57 real consumer surveys from a leading consumer products company (9,300 human responses), the SSR method achieved:
- 90% correlation attainment with product ranking in human surveys
- More than 85% distributional similarity to actual survey results
- Realistic response patterns that mirror how humans actually rate products
This isn't just incrementally better, it's the first approach that produces synthetic consumer data reliable enough to guide real product development decisions.
What This Means for Business
-
For Product Development Teams: You can now screen dozens of concepts with synthetic panels before committing budget to human surveys. Test ideas faster, iterate more, and reserve expensive panel studies for only the most promising candidates.
-
For Consumer Insights Leaders: Synthetic consumers don't just replicate ratings, they provide detailed explanations for their scores.
-
For Research Innovation: The method works without any training data or fine-tuning. It's plug-and-play, preserving compatibility with traditional survey metrics while unlocking qualitative depth that was previously impossible at scale.
-
Perhaps most importantly: synthetic consumers showed less positivity bias than human panels, producing wider, more discriminative signals between good and mediocre concepts.
The Technical Foundation That Makes It Work
The paper demonstrates something fundamental about LLMs: they've absorbed vast amounts of human consumer discourse from their training data. When properly prompted with demographic personas and asked to respond naturally, they can simulate realistic purchase intent patterns - not because they're copying training examples, but because they've learned the underlying patterns of how different people evaluate products. The team tested this rigorously:
- Compared LLM architectures (GPT-4o, Gemini 2.0 Flash)
- Validated demographic conditioning (age, income, product category all influenced responses realistically)
- Benchmarked against supervised ML approaches (which couldn't match LLM performance even with training data)
This isn't prompt engineering wizardry, it's a fundamental shift in how we should think about eliciting structured information from language models.
About the Research Team
This work comes from PyMC Labs, led by corresponding authors Benjamin F. Maier and Kli Pappas (Colgate-Palmolive), alongside the broader PyMC Labs and Colgate-Palmolive research team including Ulf Aslak, Luca Fiaschi, Nina Rismal, Kemble Fletcher, Christian Luhmann, Robbie Dow and Thomas Wiecki.
What's Next
This research opens doors well beyond purchase intent:
- Extending SSR to other survey items (satisfaction, trust, relevance)
- Optimizing reference statement sets for different domains
- Combining synthetic and human panels in hybrid research designs
- Exploring multi-stage pipelines where one LLM generates responses and another calibrates them
The fundamental insight — that textual elicitation plus semantic mapping outperforms direct numerical elicitation — likely applies far beyond consumer research.
Read the Full Preprint
This blog post covers the highlights, but the complete paper includes:
- Detailed methodology and mathematical framework
- Full experimental results across all 57 surveys
- Comparative analysis of different LLM architectures
- Reference statement design principles
- Demographic conditioning experiments
- Open-source Python implementation of the SSR methodology
Download the full preprint here to see the methods, experiments, and detailed results.
Want to learn more about synthetic consumers?
Check out PyMC Labs’ previous work:
- Can LLMs play The Price is Right?Can LLMs play The Price is Right?
- Can Synthetic Consumers Answer Open-Ended Questions?
- How Realistic Are Synthetic Consumers?
Discover how PyMC Labs is helping organisations harness the power of synthetic consumers to transform research and decision-making. See what we’re building in our Innovation Lab — and connect with us to learn more.