PyMC‑Marketing and Meridian Revisited: Approaches to Baseline Modeling for MMMs
PyMC‑Marketing and Meridian Revisited: Approaches to Baseline Modeling for MMMs

December 05, 2025
By Teemu Säilynoja, Luca Fiaschi
Overview
A few weeks ago we released a benchmark comparing PyMC-Marketing and Google Meridian on synthetic but realistic media mix modeling datasets (here). That study showed clear, quantitative differences: PyMC-Marketing achieved lower contribution-recovery error, converged more reliably, and scaled more efficiently across dataset sizes.
Both libraries have since evolved. This follow-up evaluates the latest releases — PyMC-Marketing v0.17.0 and Meridian v1.2.1 — focusing on how Meridian’s new Automated Knot Selection affects predictive performance and recovery of media contributions. The datasets, generating process, and experimental conditions remain identical to the original study.
The central question is simple:
Does Meridian’s automated spline baseline reduce the performance gap, or do the structural advantages of PyMC-Marketing’s explicit seasonality modeling remain?
What Changed in the New Versions?
1.1 Meridian v1.2.1 — Automated Knot Selection
Meridian now includes an automatic procedure for selecting spline knot counts in its time-varying baseline.
- In practice, the automated routine selects substantially more knots than our earlier hand-specified models.
- This gives Meridian a more flexible baseline capable of closely tracking sales fluctuations and improving in-sample fit.
- But it also raises the risk of the baseline absorbing variation attributable to media channels, which is a weak point emerging from this analysis.
This update clarifies some of the open questions we identified in the first benchmark. The question we will investigate in this article is whether this also improves contribution recovery.
PyMC-Marketing v0.17.0 — Updated Saturation Priors
We updated PyMC-Marketing to use the current recommended hierarchical priors for saturation parameters, aligning with the official example notebooks. These represent the standard starting point for multidimensional MMMs.
Neutral Priors Instead of Spend-Share Informed Priors
As suggested by some readers of our previous article in both libraries, we removed spend-share informed priors for this benchmark.
These priors are practical in real-world MMM, but in synthetic datasets historical spend does not reflect true effectiveness. Using neutral priors isolates each library’s ability to recover effects from data alone.
Consistent Data and Reproducibility
All datasets, noise structures, and true channel contributions are unchanged from the original study. The data generation code is now published as a standalone module to simplify user replication. The entire benchmark has been open sourced for reproducibility here.
Baselines and Seasonality: The Methodological Comparison
The most important methodological difference remains unchanged:
- PyMC-Marketing uses explicit Fourier series for seasonality and optionally a Gaussian Process for long-term trend.
- Meridian models both trend and seasonality using a single spline baseline, now with automated knot selection.
This distinction is not cosmetic. It determines how much structure is learned vs. inferred, and how easily baseline variation can leak into media coefficients.
The new feature, Automated Knot Selection increases Meridian’s flexibility, introducing more splines and allowing its baseline to match observed data more closely. The scientific question is whether this flexibility now allows it to separate media effects as effectively as PyMC-Marketing’s explicit seasonal structure.
A Quick Methodology Note: Prior Selection for Stability
During testing, we fit Meridian with its log-normal and normal media-effect priors.
- Log-normal priors produced frequent divergences and low ESS, especially on larger datasets.
- Normal priors were far more stable.
For fairness, we used the best-converged Meridian configuration for each dataset in all final comparisons.
This is a practical point for users: Meridian’s default prior choice may require adjustment for stability. To maintain our comparison as fair as possible, all adjusted to default parameters that we made were leading to improvements for Meridian in order to report the best results possible.
Updated Results: Convergence, Fit, and Recovery
We examine three dimensions:
- Convergence and sampling efficiency
- Goodness-of-fit (in-sample predictive accuracy)
- Contribution recovery (causal separation
Convergence and Sampling Efficiency
| Sampler | Start-up | Scale-up | Mature |
|---|---|---|---|
| PyMC-Marketing - nutpie | 9.38 | 1.59 | 1.71 |
| PyMC-Marketing - default | 13.23 | 0.69 | 1.13 |
| PyMC-Marketing - numpyro | 28.82 | 1.32 | Unsuccessful sample |
| PyMC-Marketing - blackjax | 27.19 | 1.74 | Unsuccessful sample |
| Meridian - tensorflow | 2.28 | 0.99 | 1.10 |
| Meridian - tensorflow (log-normal) | 2.19 | 0.07 | 0.76 |
Across small and mid-sized datasets, both libraries converged. But PyMC-Marketing’s samplers — especially NumPyro and BlackJAX — remained markedly more efficient.
- Small datasets: PyMC-Marketing samplers achieved ~28 ESS/s, vs. ~2 ESS/s for Meridian.
- Growing business datasets: PyMC-Marketing (BlackJAX) maintained 1.7 ESS/s, vs 1.0 ESS/s for Meridian.
- Medium datasets: PyMC-Marketing’s Nutpie and default samplers performed similarly to Meridian, while NumPyro and BlackJAX struggled due to dimensionality — as expected.
PyMC-Marketing’s ability to switch between backends remains a practical advantage: teams can choose the sampler that best matches their dataset size and compute environment.
Also note that we did not test this again on the enterprise dataset as reported in the previous article Meridian does not converge on at all at that scale.
Goodness-of-Fit: A Marked Improvement for Meridian
Automated Knot Selection significantly improved Meridian's in-sample predictive accuracy.
- Higher R² on all dataset sizes
- Lower MAPE
- Tighter credible intervals around predictions
Because the automated routine tends to select a large number of knots, the baseline can track residual structure closely. On small and growing datasets, Meridian matched or exceeded PyMC-Marketing’s in-sample accuracy.
However, this flexibility comes with a caveat. Meridian’s residuals show stronger autocorrelation as measured by a relatively lower Durbin–Watson, meaning the baseline is capturing well short-term patterns rather than modeling seasonality explicitly. This could inflate in-sample fit while hurting out-of-sample performance, since forecasts rely on structure the model has not truly learned. While we have not yet tested out-of-sample performance in this benchmark, future versions will include those results. In contrast, PyMC-Marketing’s explicit Fourier seasonality leaves residuals closer to white noise, indicating better separation of trend, seasonality, and media effects.
| Metric | Library | Small Business | Growing Business | Medium Business |
|---|---|---|---|---|
| R² | PyMC-Marketing | 0.871 ± 0.020 | 0.884 ± 0.015 | 0.954 ± 0.006 |
| R² | Meridian | 0.930 ± 0.009 | 0.941 ± 0.004 | 0.968 ± 0.002 |
| MAPE (%) | PyMC-Marketing | 7.10 ± 0.60 | 6.70 ± 0.50 | 5.00 ± 0.30 |
| MAPE (%) | Meridian | 5.10 ± 0.40 | 4.70 ± 0.20 | 4.20 ± 0.20 |
| Durbin-Watson | PyMC-Marketing | 1.97 ± 0.17 | 1.85 ± 0.15 | 1.88 ± 0.14 |
| Durbin-Watson | Meridian | 1.89 ± 0.17 | 1.67 ± 0.09 | 1.42 ± 0.06 |
| CRPS | PyMC-Marketing | 267 ± 154 | 301 ± 188 | 5568 ± 3608 |
| CRPS | Meridian | 237 ± 215 | 325 ± 300 | 7488 ± 7109 |
Contribution Recovery: The Critical Test
Despite improved predictive fit, Meridian still underperforms PyMC-Marketing in contribution recovery.
- Higher bias
- Higher SRMSE
- Higher CRPS
- Greater leakage of media signal into the baseline
This aligns with our observations from the original benchmark: a flexible spline baseline can improve in-sample accuracy while degrading causal separation between baseline and media effects.
| Metric | Library | Small Business | Growing Business | Medium Business |
|---|---|---|---|---|
| Bias | PyMC-Marketing | 82 ± 207 | 56 ± 158 | 522 ± 2175 |
| Bias | Meridian | 219 ± 259 | 49 ± 185 | 1664 ± 3317 |
| SRMSE | PyMC-Marketing | 0.41 ± 0.23 | 0.42 ± 0.34 | 0.16 ± 0.09 |
| SRMSE | Meridian | 0.66 ± 0.24 | 0.54 ± 0.49 | 0.29 ± 0.24 |
| CRPS | PyMC-Marketing | 145.39 ± 171.28 | 95.75 ± 139.13 | 1287.46 ± 1796.76 |
| CRPS | Meridian | 229.25 ± 311.69 | 97.54 ± 109.28 | 2265.50 ± 3050.04 |
Where Does the Highest Source of Error Come From? Saturation Induced Identifiability issues
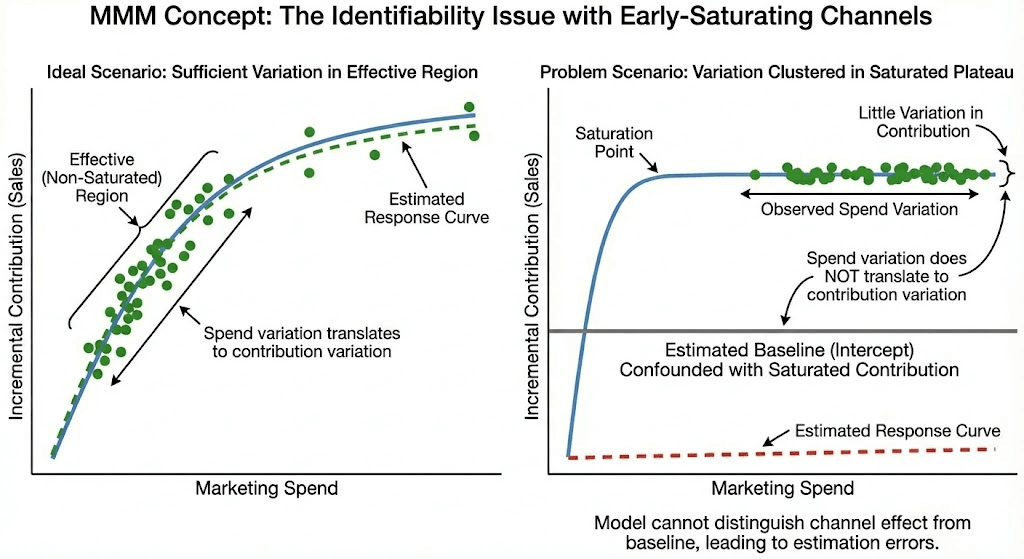
When we examined contribution-recovery errors more closely, a consistent pattern emerged: channels that saturate quickly are inherently difficult to estimate. Practitioners often focus on ensuring enough variation in spend, but the key nuance is that spend variation must translate into variation in contribution. This only happens when spend moves within the effective (non-saturated) region of the response curve.
Once a channel is saturated, additional spend produces roughly the same outcome, breaking the correlation between spend and sales. If most of the observed variation occurs in this plateau, the model cannot distinguish the channel’s effect from the baseline, even if spend fluctuates. Without enough periods below the saturation point, the channel’s contribution becomes confounded with the intercept.
This identifiability issue makes early-saturating channels systematically harder to recover for any MMM approach. It also highlights an important practical limitation: accurate attribution requires sufficient variation in the part of the response curve where spend changes actually produce different incremental contributions. If anything, a more flexible baseline makes the identifiability problem more pronounced.
Conclusion
The updated benchmark highlights a more nuanced comparison between the two libraries as they continue to evolve.
-
In terms of sampling efficiency, PyMC-Marketing still holds a clear advantage. Across all dataset sizes, there is always at least one PyMC sampler that outperforms Meridian, with NumPyro and BlackJAX delivering 10–20x efficiency gains on smaller datasets and Nutpie providing strong performance at larger scales.
-
For in-sample goodness-of-fit, Meridian benefits meaningfully from automated knot selection. The more flexible baseline allows it to track observed sales more closely, sometimes matching or exceeding PyMC-Marketing’s predictive accuracy. However, the lower Durbin–Watson statistics indicate stronger residual autocorrelation, suggesting the baseline is absorbing short-term variation rather than modeling seasonality explicitly which can be problematic in some scenarios.
-
The key trade-off emerges in contribution recovery. PyMC-Marketing continues to outperform Meridian on all small, growing, and medium datasets. The gains in Meridian’s predictive fit do not appear to come from improved causal separation, but rather from the spline baseline capturing variation that should be attributed to media channels. In other words, the improved in-sample accuracy likely reflects a form of overfitting at the baseline level.
-
For practitioners whose goal is robust attribution rather than pure predictive accuracy, PyMC-Marketing’s explicit Fourier-based seasonality remains the more robust choice, offering clearer separation between trend, seasonality, and media effects.
Both libraries are maturing quickly, and each update brings meaningful improvements to the open-source MMM ecosystem. We encourage practitioners to experiment with the latest versions, replicate these results using the published data-generation module, and contribute to the ongoing refinement of these tools.
Try It Yourself or Get in Touch
Curious to explore the models yourself? Everything (from the data generator to the full benchmark scripts) is available, and open sourced for reproducibility here . And if you’re considering an MMM overhaul or want guidance on the right modeling approach for your business, reach out. We love helping teams build measurement systems they can trust.