PyMC-Marketing vs. Meridian: A Quantitative Comparison of Open Source MMM Libraries
PyMC-Marketing vs. Meridian: A Quantitative Comparison of Open Source MMM Libraries

September 08, 2025
By Teemu Säilynoja, Luca Fiaschi, Jake Piekarski
When a data science team starts building a marketing mix model, they face a critical choice: PyMC-Marketing or Google's Meridian. Both libraries are popular choices by number of downloads, and on the surface, they look remarkably similar. Both promise state-of-the-art Bayesian inference, handle multi-geo hierarchical models, and come from credible teams. Yet, reliable, direct comparisons are non-existent.
Most existing articles offer high-level, sometimes misleading assessments or use overly simplistic examples. As a result, teams often choose based on brand name (Google), familiarity with an ecosystem (PyMC), or whatever they read last. Months into development, they discover the libraries' limitations, wasting significant time and resources.
To address this gap, we created a rigorous technical benchmark. We performed an apples-to-apples comparison of both libraries using realistic synthetic datasets that mimic everything from single-market startups to global enterprises like Nike or Colgate. We ensured a fair test by using aligned model structures, identical priors and sampling configurations. As the PyMC Labs team, our goal was scientific objectivity, and the benchmark code is publicly available on GitHub for full reproducibility.
Our extensive testing revealed that PyMC-Marketing is the more robust choice for most marketing mix modeling applications. It provides more reliable channel contribution estimates, cutting the error rate in half, runs 2-20x faster depending on dataset size. Its ability to scale to massive enterprise-level datasets and its flexible sampler options are key advantages.
The performance gap emerges from architectural differences: PyMC-Marketing's swappable samplers (NumPyro, BlackJAX, Nutpie) versus Meridian's fixed TensorFlow Probability backend, and different approaches to model parametrization and parameter pooling. The only scenario where Meridian might be a consideration is when model storage size is the absolute priority, and you are willing to sacrifice accuracy, speed and uncertainty quantification.
Understanding the Scale: From Startup to Enterprise
We tested these libraries by generating marketing data from four dataset sizes that represent the full spectrum of MMM applications – from early-stage startups to global enterprises like Nike or Colgate.
| Scale | Time Span | Geos | Media Channels | Controls | Data Size | Real-World Example |
|---|---|---|---|---|---|---|
| Start-up | 2 years | 1 | 4 | 2 | 104 x 8 | Early-stage D2C with limited channels in one market (e.g: early Warby Parker) |
| Growth | 2 years | 2 | 6 | 2 | 262 x 11 | Later-stage D2C with multiple markets or verticals (Hims & Hers, Glossier) |
| Mature | 3 years | 8 | 8 | 4 | 1,248 x 15 | Multi-region digital brand across major markets (e.g: HelloFrsh, Peloton) |
| Enterprise | 4 years | 50 | 30 | 8 | 10,400 x 43 | Global CPG with several product lines and channels (e.g: Nike, P&G brands) |
This range, from 104 to 10,400 observations, reflects a 100x increase in data complexity. It allows us to evaluate the practical scalability of MMM implementations, capturing everything from a bootstrapped startup's first marketing efforts to a Fortune 500 company managing global campaigns. The complexity increases not only with the number of geo-product combinations (which adds rows to the modeling matrix) but also with the number of marketing channels and control variables (which adds columns).
Our synthetic data is designed to reflect common marketing channel characteristics like spikiness, correlations, and seasonality. For example, as shown in the image below, the Social Media channel exhibits the pattern of a channel that is only active during specific promotional periods. In contrast, Local Ads exhibits the pattern of a channel that is frequently active during promotional periods, but isn’t an “always-on” channel.
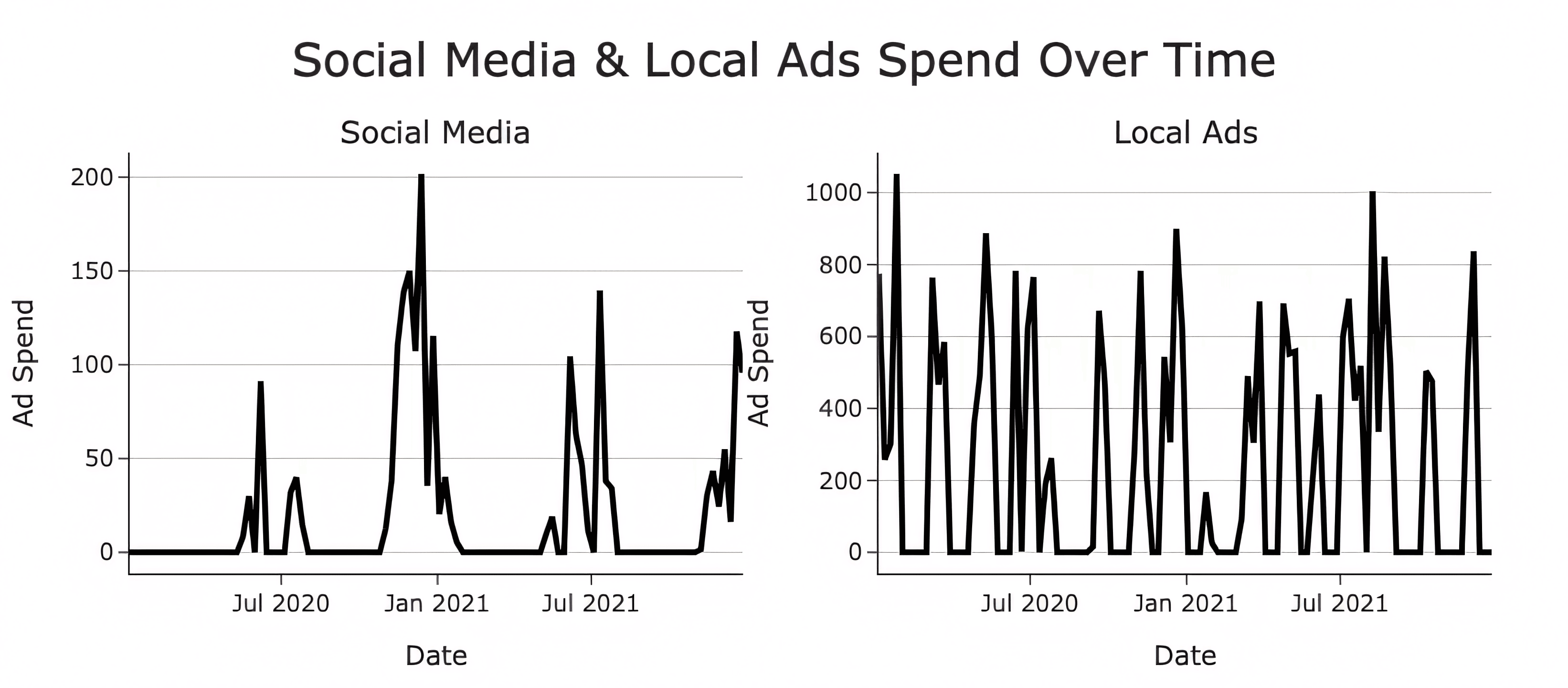
We established the "ground truth" for incremental media contributions by applying geometric adstock and Hill saturation transformations with regional variations of ±15% during data generation. This process accurately reproduces the non-linear, diminishing returns profile seen in real marketing campaigns. The known parameters and channel contributions in this synthetic data allow for a precise evaluation of the reconstruction error between the two libraries. This is crucial because a combination of correlations, randomness, non-linear response functions, and channel switching behaviors makes modeling real-world marketing data exceptionally challenging.
Benchmark Methodology
PyMC-Marketing and Meridian are both Bayesian Media Mix Model libraries, but they differ in their core architecture, which affects their modeling and sampling approaches.
- Media Effect Parametrization: The libraries use slightly different implementations of the Hill response function.
- Seasonality Modeling: Unlike PyMC-Marketing which incorporates Fourier transformations for an explicit modeling of periodic seasonality components, Meridian captures seasonal variability using splines to model a flexible baseline, as explained in the library’s documentation.
- Group-Level Effects: The libraries handle hierarchical or geographical data with distinct implementations.
- Default Priors: The default prior distributions differ for most model parameters.
Despite these differences, we aligned the configurations as much as possible for a fair comparison. While we used default priors for most parameters, the crucial adstock and saturation priors were set identically for both models, informed by channel spend data. The precise definition of the two models can be found in the repository here.
It's important to note that Meridian's models have more parameters than PyMC-Marketing, giving them potentially higher flexibility.
| # Parameters | ||
|---|---|---|
| Dataset | PyMC-Marketing | Meridian |
| Start up | 29 | 36 |
| Scale up | 51 | 59 |
| Mature | 149 | 159 |
| Enterprise | 1931 | 2229 |
Both models are fit using Markov Chain Monte Carlo (MCMC) sampling. Meridian is built on TensorFlow Probability. In contrast, a key advantage of PyMC-Marketing is its flexibility, allowing the user to choose from multiple high-performance sampling backends, including Numpyro, BlackJax, and Nutpie. These alternative samplers often include optimizations that make them better suited for scaling to larger datasets.
Our benchmark was executed on an n1-standard-32 Google Compute Engine machine, utilizing the same number of chains (4), draws (2,000), and acceptance probability (0.9) for all models. We use pymc-marketing 0.15.1 and Meridian 1.1.6. When reporting the results for PyMC-Marketing, we specifically used the Nutpie sampler, which is a reimplementation of the default NUTS algorithm in Rust (details here). However, all of its available samplers yield similar results upon model convergence.
This analysis focused on CPU performance, as both libraries support CPU computation and this represents the most common deployment scenario. Both PyMC-Marketing and Meridian also offer GPU support for accelerated computation. We are currently conducting GPU benchmarks and will update this analysis with those results.
Key Findings Across Scale
Computational Performance
PyMC-Marketing offers flexible backend samplers, allowing it to scale from small businesses to large enterprises without necessarily needing specialized hardware like GPUs, adapting to growing datasets. The following table compares the sampling speed of each option with Meridian.
Effective Samples per Second (ESS/s) measures algorithm efficiency in estimating marketing parameters by quantifying independent, uncorrelated samples generated per second. Higher ESS/s indicates faster, more efficient, and reliable estimation, unlike total runtime which can be misleading if sample quality is poor. ESS/s helps set a time budget to achieve sufficient effective samples for reliable statistics.
| median ESS / s | ||||
|---|---|---|---|---|
| Sampler | Start-up | Scale-up | Mature | Enterprise |
| PyMC-Marketing - nutpie | 22.97 | 5.86 | 17.44 | 0.19 |
| PyMC-Marketing - default | 25.04 | 4.48 | 5.30 | 0.10 |
| Meridian - tensorflow | 5.66 | 2.18 | 3.58 | Unsuccessful sample |
| PyMC-Marketing - numpyro | 110.00 | 4.38 | Unsuccessful sample | Unsuccessful sample |
| PyMC-Marketing - blackjax | 83.19 | 5.42 | Unsuccessful sample | Unsuccessful sample |
As we can see above PyMC-Marketing can be between 2-20x faster than Meridian depending on the sampler and dataset size, while PyMC-Marketing is the only option that can scale to a massive enterprise level dataset.
Practical implications:
- Startups: You can familiarize yourself with Bayesian MMM by running quick iterations with NumPyro (20x more efficient than Meridian).
- Scale-ups: Although the difference in sampling speed isn't huge, PyMC-Marketing is about twice as fast as Meridian.
- Mature and Enterprise: When Numpyro fails on larger data, seamlessly switch to Nutpie. PyMC-Marketing offers reliability, speed and scale with Nutpie.
The flexibility of PyMC-Marketing to support multiple backends and algorithms means a startup can start with Numpyro for daily model updates, then transition to Nutpie as they expand to multiple markets – all without changing libraries.
Fit Quality
In the table below, PyMC-Marketing consistently outperforms Meridian in in-sample accuracy, with 19% higher R2 and 30% smaller MAPE on the start-up dataset. The accuracy gap even increases with larger datasets. Meridian, however, struggles with model fit, diverging with the largest datasets.
| Metric | Start-up | Scale-up | Mature | Enterprise |
|---|---|---|---|---|
| R-Squared | ||||
| PyMC-Marketing | 0.87 ± 0.02 | 0.88 ± 0.02 | 0.95 ± 0.01 | 0.99 ± 0.01 |
| Google Meridian | 0.73 ± 0.02 | 0.89 ± 0.01 | 0.74 ± 0.01 | NA |
| MAPE (%) | ||||
| PyMC-Marketing | 7.2 ± 0.6 | 6.8 ± 0.6 | 5.0 ± 0.3 | 2.6 ± 0.2 |
| Google Meridian | 10.4 ± 0.5 | 6.6 ± 0.3 | 12.3 ± 0.4 | NA |
| Durbin-Watson | ||||
| PyMC-Marketing | 1.96 ± 0.17 | 1.82 ± 0.15 | 1.88 ± 0.14 | 1.71 ± 0.13 |
| Google Meridian | 1.13 ± 0.10 | 1.05 ± 0.05 | 0.40 ± 0.09 | NA |
Why this matters: Meridian's low Durbin-Watson statistics (ideal is ~2.0) indicate systematic autocorrelation in the residuals, which is illustrated in the picture below, suggesting the model misses important patterns in the data. This problem persists across dataset sizes.
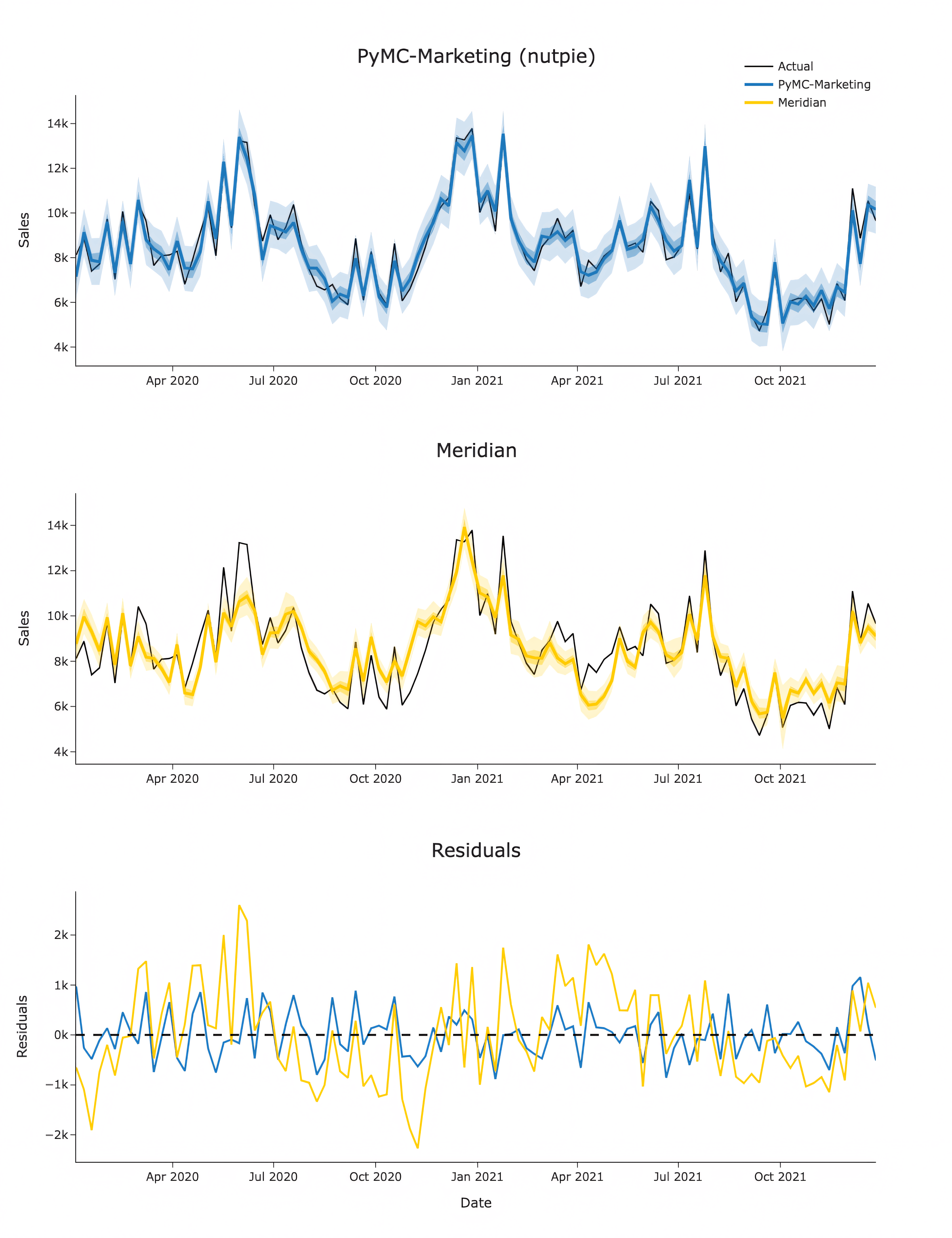
Why this matters: A startup with limited data needs every bit of signal extracted correctly. PyMC-Marketing's high R² and low MAPE means you can trust the models' recommendations even with just 2 years of single-market data. For mature companies like HelloFresh and enterprises such as Colgate operating across hundreds of markets, the stable performance ensures consistent insights across regions.
Model Convergence
All models demonstrated acceptable convergence (R̂ < 1.1) for all company scales except when noted:
- PyMC-Marketing: Exhibited 15 divergences (a rate of <1%) on startup data. These divergences suggest the model explored challenging parameter regions, often indicative of greater flexibility.
- Meridian: Showed zero divergences on the same data but presented persistent autocorrelation, and poor Durbin-Watson scores. This suggests Meridian found a stable but potentially suboptimal solution.
At Mature company scale, both models converged cleanly. However, at Enterprise scale, only PyMC-Marketing with Nutpie achieved zero divergences, although 11% of parameters had a R̂ > 1.1. This suggests that at such a large scale, increasing chain length as well as further tweaking the parameters beyond using the defaults would improve sampling.
Channel Incremental Contribution Recovery
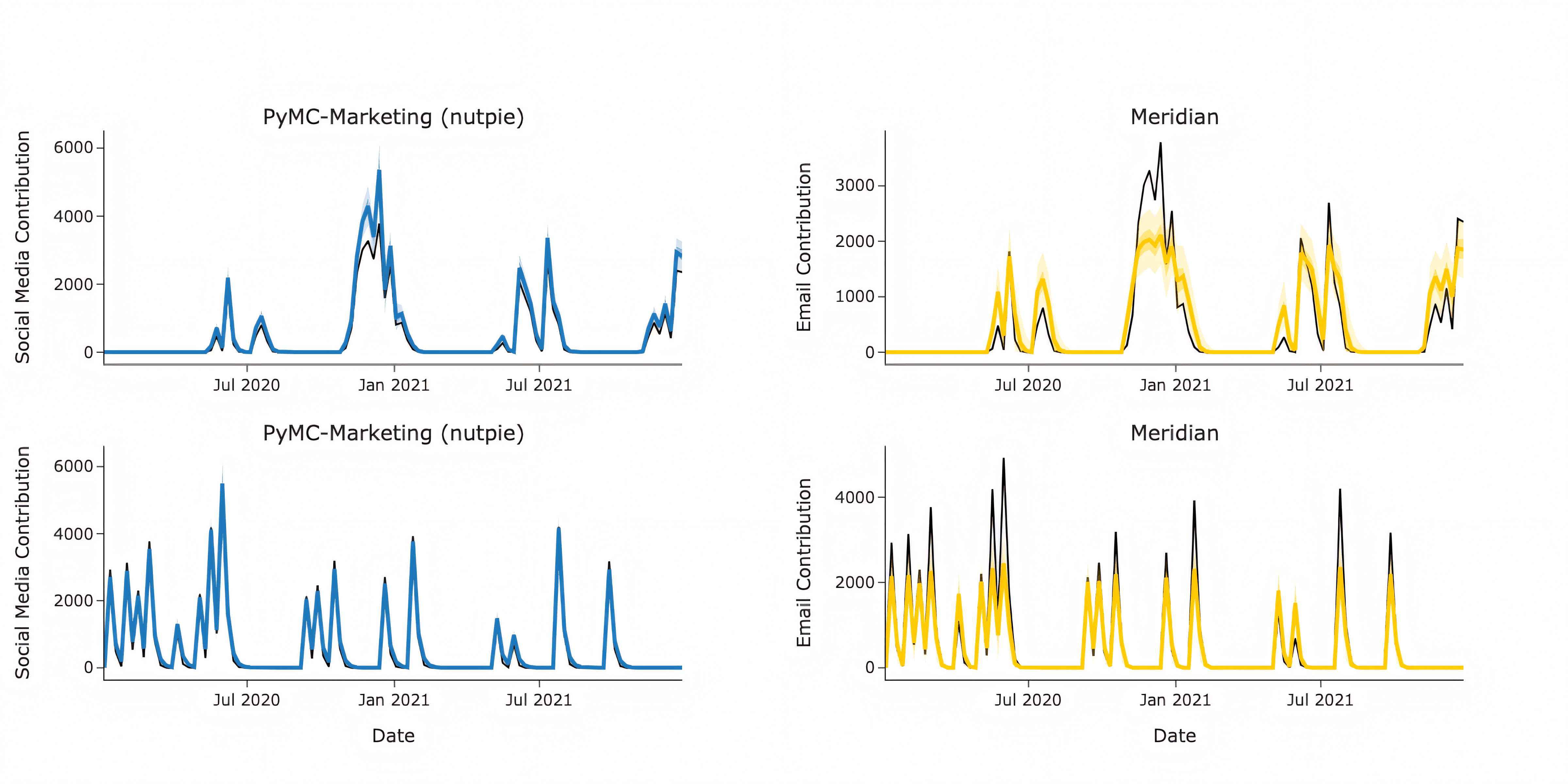
The key application of Media Mix Model is to estimate Channel Incrementality towards sales. As illustrated in the picture below, PyMC-Marketing offers more precise estimates with narrower credible intervals for decomposing sales into channel contributions. This is evident when comparing it to Meridian's posterior estimates, which are less accurate and have higher uncertainty.
The tighter uncertainty bounds provided by PyMC-Marketing are vital for effective decision-making. For instance, if PyMC-Marketing attributes 25% of sales to a channel, this estimate comes with narrow confidence intervals that allow for actionable insights. In contrast, Meridian's wider bounds often range from near-zero to strong positive contributions, making optimization decisions risky due to increased uncertainty.
To quantify performance across all channels, we can assess bias and scaled RMSE for the estimated contributions. Bias, quantified by mean error, helps identify and measure over- or under-prediction. Conversely, scaled RMSE serves as an accuracy measure, expressing accuracy as a percentage error, but it is more robust than MAPE for volatile channels with zero values.
| Metric | Start-up | Scale-up | Mature | Enterprise |
|---|---|---|---|---|
| Bias | ||||
| PyMC-Marketing | -83 ± 204 | -42 ± 146 | -485 ± 2025 | -265 ± 2530 |
| Google Meridian | 114 ± 343 | 68 ± 392 | -2390 ± 11231 | NA |
| SRMSE | ||||
| PyMC-Marketing | 0.41 ± 0.22 | 0.44 ± 0.41 | 0.15 ± 0.08 | 3.49 ± 3.91 |
| Google Meridian | 0.70 ± 0.39 | 0.70 ± 0.64 | 0.59 ± 0.40 | NA |
As the table demonstrates, PyMC-Marketing exhibits nearly double the accuracy in terms of SRMSE. Meridian's highly biased channel estimates for the larger datasets render them unreliable for companies of that size.
Interestingly, PyMC-Marketing tends to have a negative bias, underestimating channel contributions, whereas Meridian tends to overestimate them. As you can see in the picture below, Meridian seems to fail to estimate the correct adstock for the channels and estimates contributions even for periods where there is little to no spend and zero response.
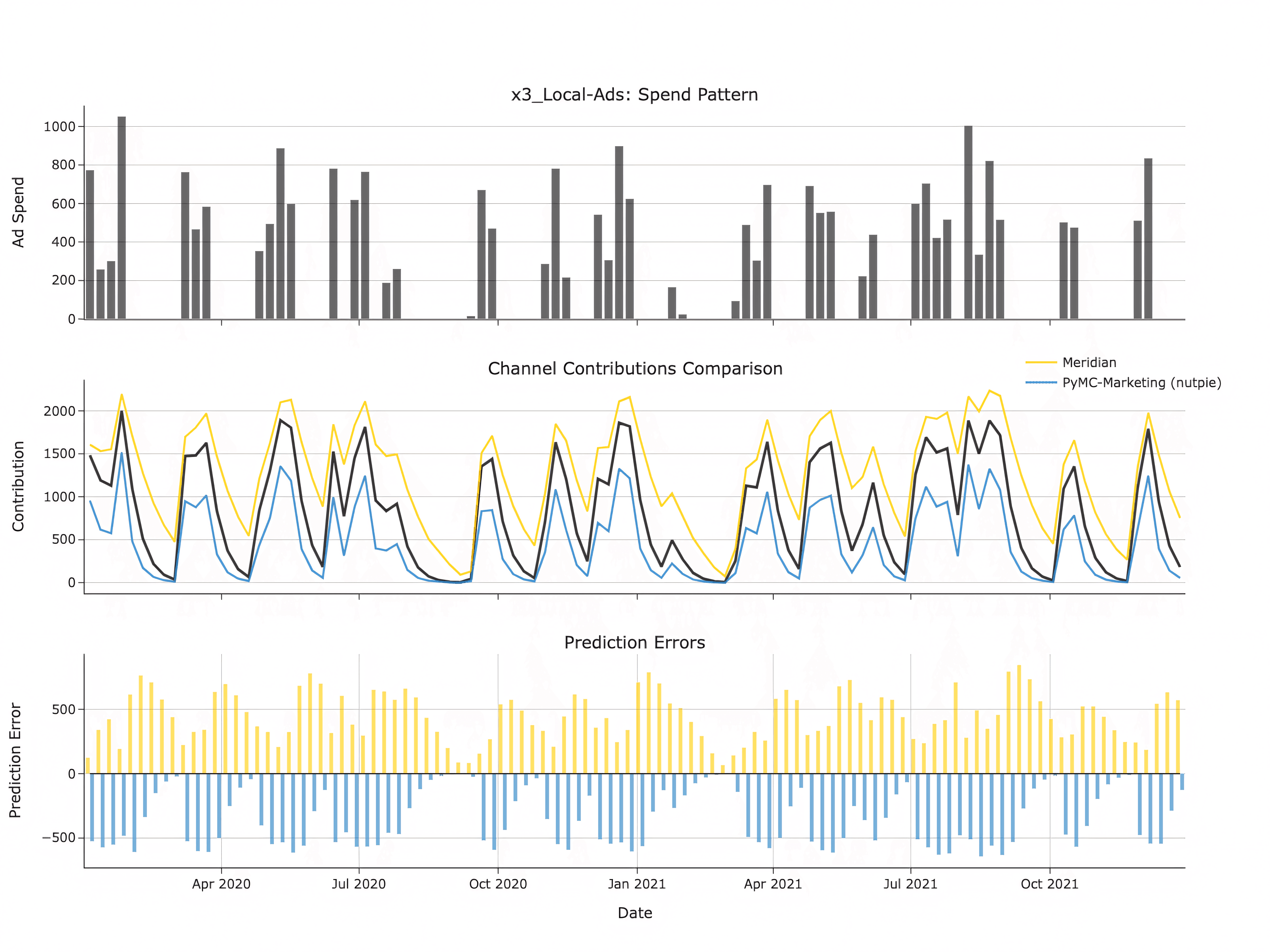
For the Enterprise datasets, PyMC-Marketing shows a relatively high SRMSE (above 1), whereas Meridian did not converge. The 90% HDI interval for the SRMSE distribution is [0.7, 9.3], which suggests that while most channels have acceptable estimates, there are a few outliers. This finding aligns with the larger R̂ values mentioned previously and indicates that for such complex models, longer sampling times or further refinement of priors and model specifications might be necessary. However, this was beyond the scope of the current analysis.
Memory Considerations
Inspection of post-sampling model storage indicates that Meridian objects occupy much smaller space on disk.
| # Size MB | ||
|---|---|---|
| Dataset | PyMC-Marketing | Meridian |
| Start up | 53 | 2 |
| Scale up | 157 | 3 |
| Mature | 931 | 6 |
| Enterprise | 19071 | 50 |
However, this comes with a caveat: PyMC-Marketing includes your data in the model object for reproducibility and easier model sharing, while Meridian doesn't. Future versions of pymc-marketing will give the ability to select the data to be stored and create a more compact model file.
It is important to note that during the actual model fitting, PyMC-Marketing uses less memory than Meridian (900MB-2.5GB vs 5GB for the smallest dataset) thus Meridian may require users to switch to a server for even moderately size datasets while PyMC-Marketing can be easily fit on a laptop.
Practical Recommendations by Company Stage
Startup - Scale Up (< $100M revenue, single or small number of markets markets):
- Use PyMC-Marketing with BlackJax or Numpyro and get 2-20x speed
- Run on laptop CPU—no infrastructure needed
- Get ~2x better predictive accuracy than Meridian for crucial early decisions
Mature Companies (1b, multi-market like HelloFresh):
- Use PyMC-Marketing with Nutpie sampler
- Standard cloud CPU instances sufficient
- Get better contribution accuracy for cross-market allocation
Enterprise (Global brands like e.g. Nike, P&G, Colgate):
- PyMC-Marketing with Nutpie
- Only viable open-source option on CPU given Meridian's scaling limitations
- Handles 50+ markets/brands, 30+ channels reliably
Consider Meridian if:
- You can allow for reduced predictive accuracy and explainability
- You are less concerned with credible regions, and can work with higher uncertainty
- Storage or fast model load/save time is a critical constraint
Conclusion: Built for Growth
The benchmark reveals PyMC-Marketing's superiority in three critical dimensions: sampling efficiency (110 vs 5.56 ESS/s 20x faster at small scale), contribution recovery (0.4 vs 0.7 SRMSE 40% lower error for channel contributions), and production scalability (2-20x speed and successful large-scale completion). These aren't marginal improvements—they represent the difference between a failed MMM implementation and a reliable tool for the needs of your data science team.
Meridian remains viable for teams with strong TensorFlow expertise and small-scale models. Its integrated ecosystem with Google dataset provides some advantages. However, the convergence failures at scale, lower sampling efficiency, and higher channel reconstruction error create significant operational constraints.
For most organizations, PyMC-Marketing's performance advantages translate directly to business value: faster experimentation cycles, more accurate budget allocation, and reliable scaling. The complete benchmark suite is available for replication—run it on your infrastructure to validate these findings against your specific requirements.